INDUSTRY PRACTICES AND TOOLS
Need for VCS
Version control (also
known as source control) is the management of file changes within a version
control system. These systems automatically maintain character level changes
for all files stored within allowing for a complete retrace of all versions of
each file, the author of those versions and a complete rollback of all changes
from the beginning of version control.
For developer
oriented work, it is critical to utilize version control systems for all
non-binary files (read Notepad readable) to enable multiple developers or teams
to work in an isolated fashion without impacting the work of others. This
isolation enables features to be built, tested, integrated or even scrapped in
a controllable, transparent and, maintainable manner.
For the
purpose of this post, Git as
the world’s leading version control system will replace the worlds “version
control system”

Three models of VCSs
•Local
version control systems

• Oldest VCS
• Everything is in your
Computer
• Cannot be used for collaborative software development

• Can be used for
collaborative software development
• Everyone knows to a
certain degree what others on the project are doing
• Administrators have
fine-grained control over who can do what
• Most obvious is the
single point of failure that the centralized server represents
· Distributed Version
Control Systems


• No single
point of failure
• Clients don’t just check out the latest
snapshot of the files: they fully mirror the repository
• If any server dies, and these systems were
collaborating via it, any of the client repositories can be copied back
• Can
collaborate with different groups of people in different ways simultaneously
within the same project.
Git commands, commit and
push
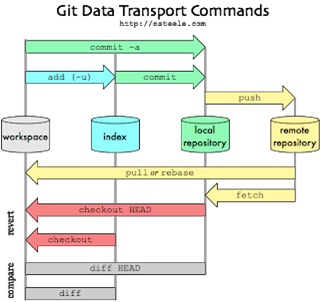
Commit and
push
Basically Git commit means records changes to
the repository while Git push update remote refs along with associated objects.
So the first one is used in connection with your local repository while the
latter one is used to interact with the remote repository
Difference between Git and
GitHub
Git is a distributed version control tool
that can manage a development project's source code history, while GitHub is a
cloud based platform built around the Git tool. Git is a tool a developer
installs locally on their computer, while GitHub is an online service that
stores code pushed to it from computers running the Git tool. The key
difference between Git and GitHub is that Git is an open-source tool developers
install locally to manage source code, while GitHub is an online service to
which developers who use Git can connect and upload or download resources.
One way to examine the differences between
GitHub and Git is to look at their competitors. Git competes with centralized
and distributed version control tools such as Subversion, Mercurial, Clear Case and IBM's Rational Team Concert. On the other hand, GitHub competes with
cloud-based SaaS and PaaS offerings, such as GitLab
and Atlassian's Bit bucket.

Use of staging area and Git
directory

The job of any version
control system (VCS) is to let you retrieve every committed version ever. (And, since both Git and Mercurial work on
the snapshot of whole system basis, they are easy to compare here. There are some much
older VCSes that operate on one file at a time: you must specifically check-in
/ commit each individual file. Git and Mercurial make a snapshot of
everything-all-at-once.) These committed snapshots should last forever, and
never change at all. That is, they are read-only.
Files that are read-only are no good for working on, though. So
any VCS must have, somehow /
somewhere, two separate things:
·
the place where you work on files: this is your work-tree; and
·
the place that snapshots are stored: this is your version
database, or repository, or some other word—Git calls these things objects while Mercurial has a more complicated set
of structures, so let's just call them objects here.
Git's object storage area has a bunch of read-only objects: in
fact, one for every file, and every commit, and so on. You can add new objects any time, but you cannot change
any existing objects.
As Mercurial demonstrates, there is no requirement for a separate staging area: the VCS can
use the work-tree as
the proposed commit. When you run hg commit, Mercurial packages up the work-tree and makes a commit from
it. When you make changes in the work-tree, you change the proposed next
commit. The hg status command shows you what you're proposing to commit, which
is: whatever is different between the current commit and the
work-tree.
Git, however, chooses to interpose this intermediate area,
halfway between the read-only commits and the read/write work-tree. This
intermediate area, the staging area or index or cache, contains the proposed next commit.
You start out by checking out some commit. At this point, you
have three copies of every
file:
·
One is in the current commit (which Git can always find by the
name HEAD). This one is read-only;
you can't change it. It's in a special, compressed (sometimes very compressed), Git-only form.
·
One is in the index / staging-area. This one matches the HEAD one now, but
it can be changed. It's the one proposed to go into
the next commit. This, too, is in the special Git-only
form.
·
The last one is in your work-tree, in ordinary form where you
can work on it.
What git add does is to copy files from your work-tree, into the
staging area, overwriting the
one that used to match the HEAD commit.
When you run git status, it must make two separate comparisons. One compares the HEAD commit to the index / staging-area, to see
what's going to be different in the next commit. This is what's to be
committed. The second
comparison finds what's different between the index / staging-area, and the
work-tree. This is what's not staged for commit.
When you run git commit -a, Git simply does the copy-to-staging-area based on the second
comparison. More precisely, it runs the equivalent of git add -u. (It secretly does this with a temporary staging-area, in case the commit fails
for some reason, so that your regular staging-area / index is undisturbed for
the duration of the commit. Some of this depends on additional git commit arguments as well. Normally this tends to be
invisible, at least until you start writing complex commit hooks.)
Git is
a version control system, like "track changes" for code. It's fast,
powerful, and easy-to-use version control system. But the thing that's really
special about Git is the way it empowers people to collaborate.
All the projects on drupal.org are
stored in Git, and there are millions of public projects hosted by GitHub.com.
Whether you are a developer who wants to contribute to an open source project,
a freelancer who needs to know how to maintain a patched module, or a member of
a team collaborating on a single code base, Git is a tool worth having in your
toolbox.
This blog post walks through some basic Git workflows for
collaborative development. If you've heard people talk about
"decentralized" or "distributed" version control, but you
haven't seen it in action, or you're not sure what's so cool about it, this
post is for you. To follow along, you just need to have Git installed on your
computer. Some basic experience with version control (Git or other) is helpful,
but not required
Benefits of CDNs
•
Improving website load times - By distributing content closer to website
visitors by using a nearby CDN server (among other optimizations), visitors
experience faster page loading times. As visitors are more inclined to click
away from a slow-loading site, a CDN can reduce bounce rates and increase the
amount of time that people spend on the site. In other words, a faster a
website means more visitors will stay and stick around longer.
•
Reducing bandwidth costs - Bandwidth consumption costs for website hosting is a
primary expense for websites. Through caching and other optimizations, CDNs are
able to reduce the amount of data an origin server must provide, thus reducing
hosting costs for website owners.
•
Increasing content availability and redundancy - Large amounts of traffic or
hardware failures can interrupt normal website function. Thanks to their
distributed nature, a CDN can handle more traffic and withstand hardware
failure better than many origin servers.
• Improving website security - A CDN may
improve security by providing DDoS mitigation, improvements to security
certificates, and other optimizations.
CDNs differ from web
hosting servers
- Web Hosting is used to host
your website on a server and let users access it over the internet. A
content delivery network is about speeding up the access/delivery
of your website’s assets to those users.
- Traditional web hosting would
deliver 100% of your content to the user. If they are located across the
world, the user still must wait for the data to be retrieved from where
your web server is located. A CDN takes a majority of your static and
dynamic content and serves it from across the globe,
decreasing download times. Most times, the closer the CDN server is to the
web visitor, the faster assets will load for them.
- Web Hosting normally refers to
one server. A content delivery network refers to a global network of edge
servers which distributes your content from a multi-host
environment.
Free and commercial CDNs
1 Cloud Flare

Cloud
Flare is popularly known as the best free CDN for Word Press
users. It is one of the few industry-leading players that actually offer a free
plan. Powered by its 115
datacenters, Cloud Flare delivers speed, reliability, and protection
from basic Dodos attacks. And its Word Press plugin is used in
over 100,000 active website.
Incapsula

Incapsula provides Application Delivery from the cloud: Global
CDN, Website Security, Dodos Protection, Load Balancing & Failover. It
takes 5 minutes to activate the service, and they have a great free plan and a Word Press plugin to get
correct IP Address information for comments posted to your site.
Photon by Jetpack

To all Word Press users – Jetpack needs no
introduction. In their recent improvement of awesomeness, they’ve included a
free CDN service (called Photon) that serves your site’s images through their globally
powered WordPress.com grid. To get this service activated, all you have
to do is download and install Jetpack and activate its Photon module.
Swarmify

Swarmify,
(previously known as SwarmCDN) is a peer-to-peer (P2P) based content delivery
network that offers 10GB bandwidth (only for images) in their free plan. To try
it out, download the Word Press plugin and give it a
go. It is interesting to note that Swarmify works in a slightly different manner.
AWS Cloudfront

Amazon Web
Services (AWS) is a pioneer in bringing high performance cloud computing to the
masses at an affordable rate. One of their services is Amazon Cloud
Front an
industry-leading content delivery network used by the likes of Slack and Spotify
Requirements for virtualization
Almost every application
vendor publishes a list of hardware requirements for its applications. These
requirements do not change just because an application runs on a virtual
server. If an application requires 4 GB of memory, then you need to make sure
the virtual machine on which you plan to run the application is provisioned
with at least 4 GB of memory.
Some organizations prefer
to give each virtual machine as much memory as it is ever likely to use, rather
than taking the time to figure out how much memory each virtual machine really
needs. Although this technique might waste memory, it does improve virtual machine
performance, since the machine
has been allocated plenty of memory.
If your organization uses this
technique, one way to avoid wasting memory is to know the upper memory limits
that each operating system supports. For example, 32-bit operating systems can
address a maximum of 4 GB of memory. Assigning anything over 4 GB to a virtual
machine running a 32-bit operating system would be a waste, since the operating
system won’t even see the extra memory. (There are exceptions for servers using
a Physical Address Extension).
To
better identify your hardware requirements for virtualization of applications,
the chart below illustrates the maximum amount of memory supported by various
Windows Server operating systems.
Different virtualization
techniques in different levels
VMware Server
VMware Server is used throughout this
book to illustrate virtualization techniques and technologies. It is a free
offering from VMware and is considered an introductory package for use in small
environments, testing, or for individuals. It has limited usefulness in large
environments because of its memory limitations for VMs and sluggish disk
performance. VMware Server supports 64-bit machines as hosts and guests
Sun xVM (VirtualBox)
VirtualBox,
which is now Sun xVM VirtualBox, is one of my favorite virtualization packages.
Like VMware Server, it is free and cross-platform, but unlike VMware Server, it
is open source. With adjustable video memory, remote device connectivity, RDP
connectivity, and snappy performance, it may well be the best hosted virtualization
package in your arsenal.
VirtualBox is best suited for small networks and individuals for
the same reasons as VMware Server
Hypervisor
A hypervisor is a bare metal approach to
virtualization. Bare metal refers to the server system hardware without any OS
or other software installed on it. The best way to describe hypervisor
technology is to draw a comparison between it and hosted virtualization. At
first glance, the hypervisor seems similar to hosted virtualization, but it is
significantly different.
Kernel-Level
Kernel-level virtualization is kind of an oddball
in the virtualization world in that each VM uses its own unique kernel to boot
the guest VM (called a root file system) regardless of the host's running
kernel.
Bochs
Bochs is a free, open-source, Intel
architecture x86 (32-bit) emulator that runs on Unix and Linux, Windows and Mac
OS X, but only supports x86-based operating systems. Bochs is a very
sophisticated piece of software and supports a wide range of hardware for emulating
all x86 processors and itecture. It also supports multiple processors but doesn't take full advantage of SMP at this timex86_64 processor arch
QEMU
QEMU is another free, open-source
emulation program that runs on a limited number of host architectures (x86,
x86_64, and PowerPC) but offers emulation for x86, x86_64, ARM, Sparc, PowerPC,
MIPS and m68k guest operating systems
Popular implementations and available tools
for each level of visualization
Data wrapper
Data wrapper is increasingly becoming a
popular choice, particularly among media organizations which frequently use it
to create charts and present statistics. It has a simple, clear interface that
makes it very easy to upload csv data and create straightforward charts, and
also maps, that can quickly be embedded into reports.
FutionCharts
This is a very widely-used, JavaScript-based
charting and visualization package that has established itself as one of the
leaders in the paid-for market. It can produce 90 different chart types and
integrates with a large number of platforms and frameworks giving a great deal
of flexibility. One feature that has helped make Fusion Charts very popular is
that rather than having to start each new visualization from scratch, users can
pick from a range of “live” example templates, simply plugging in their own
data sources as needed.
HighCharts
Like Fusion Charts this also requires a license
for commercial use, although it can be used freely as a trial, non-commercial
or for personal use. Its website claims that it is used by 72 of the world’s
100 largest companies and it is often chosen when a fast and flexible solution
must be rolled out, with a minimum need for specialist data visualization
training before it can be put to work. A key to its success has been its focus
on cross-browser support, meaning anyone can view and run its interactive
visualizations, which is not always true with newer platforms.
Plotly enables more
complex and sophisticated visualizations, thanks to its integration with
analytics-oriented programming languages such as Python, R and Mat lab. It is
built on top of the open source d3.js visualization libraries for JavaScript,
but this commercial package (with a free non-commercial license available) adds
layers of user-friendliness and support as well as inbuilt support for APIs
such as Salesforce.
Hypervisor
A hypervisor or virtual
machine monitor (VMM) is computer software, firmware or hardware that creates and runs virtual machines. A computer on which a
hypervisor runs one or more virtual machines is called a host machine,
and each virtual machine is called a guest machine. The hypervisor
presents the guest operating systems with a virtual operating
platform and manages the execution of the guest operating
systems. Multiple instances of a variety of operating systems may share the
virtualized hardware resources: for example, Linux, Windows, and macOS instances
can all run on a single physical x86machine.
This contrasts with operating-system-level
virtualization, where all instances (usually called containers)
must share a single kernel, though the guest operating systems can differ
in user space, such as different Linux distributions with
the same kernel.
The
term hypervisor is a variant of supervisor, a
traditional term for the kernel of
an operating system:
the hypervisor is the supervisor of the supervisor,[1] with hyper- used as a stronger variant
of super-.[a] The term dates to circa 1970;[2] in the earlier CP/CMS (1967) system the term Control
Program was used instead.
Emulation is different from VMs
Virtual machines make use of
CPU self-virtualization, to whatever extent it exists, to provide a visualized interface to the real hardware. Emulators emulate hardware without relying on
the CPU being able to run code directly and redirect some operations to a hyper-visor controlling the virtual container.
A
specific x86 example might help: Bochs is an emulator,
emulating an entire processor in software even when it's running on a
compatible physical processor; qemu is also an emulator,
although with the use of a kernel-side
kqemu package
it gained some limited virtualization capability when the emulated machine
matched the physical hardware — but it could not really take advantage of full
x86 self-virtualization, so it was a limited hypervisor; kvm is
a virtual machine hypervisor.
A
hypervisor could be said to "emulate" protected access; it doesn't
emulate the processor, though, and it would be more correct to say that it mediates protected
access.
Protected access means things
like setting up page tables or reading/writing I/O ports. For the former, a
hypervisor validates (and usually modifies, to match the hypervisor's own
memory) the page table operation and performs the protected instruction itself;
I/O operations are mapped to emulated device hardware instead of emulated CPU.
And
just to complicate things, Wine is also more a
hypervisor/virtual machine (albeit at a higher ABI level) than an emulator
(hence "Wine Is Not an Emulator").
VMs and containers/dockers, indicating their advantages and
disadvantages
Virtual machines have a full OS with its own memory management installed with the associated overhead of virtual device drivers. In a virtual machine, valuable resources are emulated for the guest OS and hyper-visor, which makes it possible to run many instances of one or more operating systems in parallel on a single machine (or host). Every guest OS runs as an individual entity from the host system.
On the other hand
Docker containers are executed with the Docker engine rather than the hyper-visor. Containers are therefore smaller than Virtual Machines and enable
faster start up with better performance, less isolation and greater
compatibility possible due to sharing of the host’s kernel.
1). Docker Containers and Virtual Machines
by themselves are not sufficient to operate an application in production. So
one should be considering how the Docker Containers are going to run in an
enterprise data center.
2). Application probability and enabling the
accordant provisioning of the application across infrastructure is provided by
containers. But other operational requirements such as security, performance
and capacity management and various management tool integrations are still a
challenge in front of Docker Containers, thus leaving everyone in a big puzzle.
3). Security isolation can be equally
achieved by both Docker Containers and Virtual Machines.
4). Docker Containers can run inside Virtual
Machines though they are positioned as two separate technologies and provide
them with pros like proven isolation, security properties, mobility, dynamic
virtual networking, software-defined storage and massive ecosystem.
No comments:
Post a Comment