Introduction to client-side
development

Main elements of
client-side application
Client-side Environment. The client-side environment
used to run scripts is usually a browser. The processing takes place on the end
users computer. The source code is transferred from the web server to
the user’s computer over the internet and run directly in the browser.
Typically, a client is a computer application, such
as a web browser, that
runs on a user's
local computer, smartphone, or other device, and connects
to a server as
necessary. Operations may be performed client-side because they require access
to information or functionality that is available on the client but not on the
server, because the user needs to observe the operations or provide input, or
because the server lacks the processing power to perform the operations in a
timely manner for all of the clients it serves. Additionally, if operations can
be performed by the client, without sending data over the network, they may
take less time, use less bandwidth, and
incur a lesser security risk.
When the server serves data in a commonly used manner, for example
according to standard protocols such
as HTTP or FTP, users
may have their choice of a number of client programs (e.g. most modern web
browsers can request and receive data using both HTTP and FTP). In the case of
more specialized applications, programmers may write their own
server, client, and communications protocol which
can only be used with one another.
Programs that run on a user's local computer without ever
sending or receiving data over a network are not considered clients, and so the
operations of such programs would not be termed client-side operations.
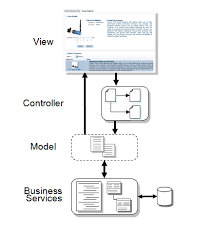
Views development
technologies for the browser-based client-components of web-based applications
•Browser-based clients’ Views
comprises two main elements
•Content –HTML •Formatting –CSS
•Server/client-side components may
generate the elements of Views
Controller development
technologies for the browser-based client-components of web-based applications
A controller is a program component that serves as a mediator
between a user and application and handles business-related tasks triggered
in ASP.NET pages. A controller
is used for scripting exposed and middle-tier endpoints for expected user
actions and results.
A controller serves
different roles in ASP.NET Web Form and Model-View-Controller (MVC)
architectural designs. ASP.NET Web Forms are built on a
sequentially-phased model, from parsing incoming requests to generating HTML
pages based on ASP.NET source file templates.
An ASP.NET Web Form controller handles all business tasks triggered
by the page, and the event handler collects server control input data that is
packaged for the controller. Because they are tightly coupled, flexibility
between the controller and user interface (UI) is hindered.
In MVC architectural patterns, a controller operates in a central role with different mechanics. The controller class is a plain class with some public methods. Each method has a one-to-one link with a possible user action, ranging from the click of a button to another trigger. The controller class methods process input data, execute application logic and determine view. An action filter is used to decorate the controller's methods with pre and post-action behavior, as follows:
public class Controller A : Controller {
public ActionResult A(){
//execute some application logic and then yield to the view engine.
return this.View("A
}
}
The controller has a layered structure that starts with the IController interface at the bottom, followed by the controller base class, controller class, other interfaces and, finally, the user-defined controller class responsible for total top interactivity.
Controller classes follow an inheritance hierarchy, where preceding class methods must be implemented by subsequent classes. For example, controller base class methods must be recognized to allow overriding by the derived controller classes and functionality implementation.
Controller activities may be summarized as follows:
In MVC architectural patterns, a controller operates in a central role with different mechanics. The controller class is a plain class with some public methods. Each method has a one-to-one link with a possible user action, ranging from the click of a button to another trigger. The controller class methods process input data, execute application logic and determine view. An action filter is used to decorate the controller's methods with pre and post-action behavior, as follows:
public class Controller A : Controller {
public ActionResult A(){
//execute some application logic and then yield to the view engine.
return this.View("A
}
}
The controller has a layered structure that starts with the IController interface at the bottom, followed by the controller base class, controller class, other interfaces and, finally, the user-defined controller class responsible for total top interactivity.
Controller classes follow an inheritance hierarchy, where preceding class methods must be implemented by subsequent classes. For example, controller base class methods must be recognized to allow overriding by the derived controller classes and functionality implementation.
Controller activities may be summarized as follows:
- Gathering input
- Executing the request-related
action method
- Preparing view data
- Triggering view refreshing
Client-Model development
technologies for the browser-based client components of web-based applications
The client-server model is a
core network computing concept also building functionality for email exchange
and Web/database access. Web technologies and protocols built
around the client-server model are: Hypertext
Transfer Protocol (HTTP)
The client-server
model is a distributed communication framework of network processes among
service requestors, clients and service providers. The client-server connection
is established through a network or the Internet.
The client-server model is a core network computing concept also building functionality for email exchange and Web/database access. Web technologies and protocols built around the client-server model are:
The client-server model is a core network computing concept also building functionality for email exchange and Web/database access. Web technologies and protocols built around the client-server model are:
- Hypertext Transfer Protocol
(HTTP)
- Domain Name System (DNS)
- Simple Mail Transfer Protocol
(SMTP)
- Telnet
Clients include Web
browsers, chat applications, and email software, among others. Servers include
Web, database, application, chat and email, etc.
A server manages most
processes and stores all data. A client requests specified data or processes.
The server relays process output to the client. Clients sometimes handle processing,
but require server data resources for completion.
The client-server
model differs from a peer-to-peer (P2P) model where communicating systems are
the client or server, each with equal status and responsibilities. The P2P
model is decentralized networking. The client-server model is centralized
networking.
One client-server model drawback is having too many client
requests underrun a server and lead to improper functioning or total shutdown.
Hackers often use such tactics to terminate specific organizational services
through distributed denial-of-service (DDoS) attacks.
Different categories of
elements in HTML
Structural
elements
•header,
footer, nav, aside, article
Text
elements
•Headings –<h1> to <h6> •Paragraph
–<p> •Line break -<br>
Images
Hyperlinks
Data
representational elements (these elements use nested structures)
•Lists
•Tables
•Form
elements
•Input
•Radio
buttons, check boxes
•Buttons
Importance of CSS

CSS
stands for Cascading Style Sheets. It is the coding language that gives a
website its look and layout. Along with HTML, CSS is fundamental to web design.
Without it, websites would still be plain text on white backgrounds.
Before
the development of CSS in 1996 by the World Wide Web Consortium (W3C), Web
pages were extremely limited in both form and function. Early browsers
presented a page as hypertext - plain text, images and links to other hypertext
pages. There was no layout at all to speak of, merely paragraphs running across
the page in a single column.
CSS
allowed several innovations to webpage layout, such as the ability to:
- Specify fonts other than the
default for the browser
- Specify color and size of text
and links
- Apply colors to backgrounds
- Contain webpage elements in
boxes and float those boxes to specific positions on the page
They
put the "style" in style sheets, and for the first time, Web pages
could be designed.
The
first commercial browser to read and utilize CSS was Microsoft's Internet
Explorer 3 in 1998. To this day, support for certain CSS functions varies from
browser to browser. The W3C, which still oversees and creates Web standards,
recently released a new standard for CSS - CSS3. With CSS3, developers hope
that all major browsers will read and display every CSS function in the same
way.
New features of CSS3
CSS3 is the latest evolution of the Cascading Style Sheets
language and aims at extending CSS2.1. It brings a lot of new features and
additions, like rounded corners, shadows, gradients, transitions or animations,
as well as new layouts like multi-columns, flexible box or grid layouts.
CSS selectors
There are 3 main selectors
•Element selector
•ID selector
•Class selector
Class selector
Selects all elements that have the
given
Syntax:
Example:
class attribute.Syntax:
.classnameExample:
.index will match any element that has a class of
"index".
ID selector
Selects an element based
on the value of its id attribute. There should be only one
element with a given ID in a document.
Syntax: #idname
Example: #toc will match the element that has the ID "toc".
Syntax: #idname
Example: #toc will match the element that has the ID "toc".
Element selector
Selects all elements that match the
given node name.
Syntax: eltname
Example:
Syntax: eltname
Example:
input will match any <input> element.
Advanced CSS selectors
Advanced Selectors in CSS. Selectors are
used for selecting the HTML elements in the attributes. Some different types
of selectors are given below: Adjacent Sibling Selector:
It selects all the elements that are adjacent siblings of specified elements.
Pseudo classes: Link:
Visited: hover
Pseudo elements
first-letter first-line first-child
CSS media queries in
responsive web development
Media types all
braille, embossed, speech, hanheld, projection, screen, tv print, tty
<link
media=“(min-width: 30em)” … <link media=“screen and (min-width: 30em)” …
@media (min-width:
30em) { … } @media screen and (min-width: 30em) { … }
Inline CSS
Inline style sheets is
a term that refers to style sheet information being applied to the current element.
By this, I mean that instead of defining the style once, then applying the
style against all instances of an element (say the
<p> tag), you only apply the style to the
instance you want the style to apply to. Actually, it's not really a style
sheet as such, so a more accurate term would be inline styles.
Internal CSS sheets
An internal
stylesheet holds CSS rules for the page in the head section of
the HTML file. The rules only apply to that page, but you can configure CSS
classes and IDs that can be used to style multiple elements in the page code.
Again, a single change to the CSS rule will apply to all tagged elements on the
page.
External CSS sheets
An external
stylesheet is a standalone .css file that is linked from a
web page. The advantage of external stylesheets is that it can be created once
and the rules applied to multiple web pages. Should you need to make widespread
changes to your site design, you can make a single change in the stylesheet and
it will be applied to all linked pages, saving time and effort.

Frameworks/libraries/plugins/tools
to develop the Views/web pages
There
are many frameworks/libraries/plugins to support view development
•They dynamically generate HTML+CSS code
•In server and/or client side
•May have JS-based advanced interactive
features
•jQuery–A
JS library, but can be seen a framework too. It wraps the complexity of pure
JS. There are lots of JS frameworks, libraries, and plugins built using jQuery.
Good for DOM processing.
•jQuery UI –Focus on GUI development
•Bootstrap–to
rapidly design and develop responsive web pages and templates
•Angular–a
JS framework/platform to build frontend applications •React–a JavaScript
library for building user interfaces (and the application, which uses that UI)
Plug-ins
are mainly to add widgets to the Views
•However, may contain interactive components
as well
•Therefore,
can be seen as micro-applications
Client-side component
development related aspects in browser-based web applications
•Browser-based
clients’ components comprises two main aspects •Controllers •Client-model
•The
components of browser-based clients are developed using JS/JS-based frameworks,
libraries, and plugins.
Main
features of client-side component development tools
•DOM
processing (dynamic content generation, change, removal) •Data processing
•Data
persistence
•Session
management (cookies)
•Communicating
(with server components)
New features in JS version
6
•Web
workers-This API is meant to be invoked by web application to spawn background
workers to execute scripts which run in parallel to UI page. The concept of web
works is similar to worker threads which get spawned for tasks which need to in
voked
separate from the UI thread.
•Web
storage/ session Storage-This is for persistent data storage of key-value pair
data in Web clients.
•Geolocation–Identify
the device location
•File
API–Handle the local files
•Image
capturing –use local hardware (camera)
Top JS
frameworks/Libraries
•jQuery:
Basic and simple. Cover the complexity of JS and provides cross-browser
compatibility.
•React:
powers Facebook, Ease of Learning, DOM Binding, Reusable Components, Backward
Compatibility
•Angular:
Support for Progressive Web Applications, Build Optimizer, Universal State
Transfer API and DOM, Data Binding and MVVM
•Vue:
lightweight , with a much-needed speed and accuracy





